





 Network Security
Network Security
 Vulnerability Management
Vulnerability Management
 Privileged Access Management
Privileged Access Management  Endpoint Security
Endpoint Security
 Threat Hunting
Threat Hunting
 Unified Endpoint Management
Unified Endpoint Management
 Email & Collaboration Security
Email & Collaboration Security


Contents:
Some time ago, I’ve written an article on how to choose the best Data Loss Prevention solution for your business. Evidently, I hadn’t had the chance of going into too many technical details; all the more reason to revisit a topic that has sparked more confusion than the entire coronavirus pandemic. So, because words are cheap, let’s get going. Before that, here’s a little sneak peek – I’m going to discuss content analysis techniques, data architecture and classification, and policy management. Enjoy!
(Re)Defining Data Loss Prevention
SANS Institute’s paper on Data Loss Prevention mentions that the DLP marker is “one of the least understood” and “hyped”. Good choice of words from where I stand, since there are at least five different names to describe the same product; my all-time favorite is “extrusion prevention”. Now, to encapsulate all of the items on our list du jour, we will need to tweak the definition.
So, Data Loss Prevention refers not to one, but to an entire family of products designed to classify, safeguard, and monitor data, regardless of form, content, and status (i.e., in use, at rest, or in transit). All these operations are carried out using pre-defined- and centralized-policies and deep content analysis techniques.
There you have it – a DLP solution has to ‘police’ data streams and flags any policy violations. Sounds pretty straightforward, doesn’t it? There’s nothing easy or straightforward when it comes to data protection. Now, Data Loss Prevention, as a discipline, uses context- and content-based inspection techniques in order to identify any security breaches. Content-based inspection sometimes referred to as deep content analysis, is a methodology employed to pinpoint policy violation latched to multi-layered files.
One example of CBI (content-based inspection) would be ‘looking’ inside at docx file that has been previously attached to a .csv or .xls file. How about an archived .pdf file? Deep-scanning technologies, some of which we will be discussing throughout this article, are used to achieve the aforementioned task. To why the content is relevant in DLP, I’ll say this – without it, it would be next to impossible to determine if there are any policy breaches.
Okay, but the content is nothing without context. What can pass as a “context” in a DLP setting? Here’s an example. Using a debit card to make a purchase from your workstation should be penalized. Reminds you of your first job, doesn’t it? That sentence can be turned into a centralized policy.
Evidently, the phrasing is kind of vague – why does the company prohibit this? Does this refer to a person or a company-issued debit card? What kind of purchases does this policy cover? What are the penalties? As you can clearly see, the lack of context makes it quite difficult to enforce the policy. Let’s mix things up a bit – it’s forbidden and should, therefore, be penalized, the use of client-registered debit cards in order to conduct personal transactions on a company-issued machine.
Now it’s starting to make more sense, doesn’t it? Let’s mix things out a bit – what would the all-knowing and all-mighty DLP say if an employee would try to use a customer’s previously registered debit card information (i.e., card no., name, expiration date, CVV2 code) to purchase a PS5 for his kid or a bigger Android TV?
Well, it should light up like a Christmas tree if the security policy is set up correctly. As you can clearly see, context matters – buying personal stuff from your workstation is okay, but using someone else’s financial info to do so is a big no-no. Context is vital in DLP, but, unfortunately, it does not make the purpose of this article.
Anyway, let’s tackle content and content-based techniques. Mirroring email security solutions that employ deep content scanning to root out phishing links, weaponized macros, and malicious code, in general, a DLP solution will peek inside everything passed within (and without) your organizational network. There are, of course, limitations to this deep scanning process – for instance, a data loss prevention solution cannot open a password-protected file.
Content scanning is achieved through various techniques – Regex or rule-based and\or regular expressions, DB fingerprinting (database fingerprinting), EDM (exact data match), PDM (partial document matching), ML-mediated statistical analysis, lexicon, categorization, and Bayesian Network modeling. For obvious, brevity-related reasons, in this article, I’ll ‘only’ be covering EDM and Regex.
Content Awareness in Data Loss Prevention. Techniques and Common Practices.
Still here? Really hope you are because this is where the fun begins.
EDM (Exact Data Match)
Exact Data Match or EDM, for short, is a content-based data modeling technique used to identify and classify CUSTOM SENSITIVE INFORMATION. In this context, sensitive information refers to a pattern-like data string, that can be queried using functions or regular expressions. We’ll talk more about those in the section dedicated to Regex.
In EDM, custom (case) sensitive information can be tracked down and classified through means such as patterns, keywords, confidence level, and the proximity of a character or character set to a known pattern. To illustrate how everything works, let’s see how an EDM-based DLP ‘reads’ confidential elements. As I’ve mentioned, EDM rests on confidence levels to make a content-aware determination.
Microsoft acknowledges three layers of confidence: high, medium, and low. Think of them as sensitivity levels. Now, to accurately detect a type of information within an email, document, database, or whatever, the system needs two things: a primary element and a supporting element. We can say that this classification endeavor has a high confidence level if the primary element has two or more supporting elements. Medium confidence has a single supporting element, and low confidence has none.
Let’s imagine that the DLP curator wants to create a policy that revolves around credit card details. This policy can serve any number of purposes – prevent users from sharing credit card details via email or chat, obscure CVVs or credit card numbers while the encapsulation medium is in transit or at rest, and so on. Writing the policy is a sinch, but how do you go about instructing the system about recognizing elements native to financial instruments such as debit or credit card?
Every email has some distinctive signs: the sender’s field, a subject filed, the greeting, the message’s body, and the closing. Using EDM, the system ‘scans’ the email for primary elements. In the context of financial instruments, a primary field can be a keyword like “credit card” or “debit” card. Once the primary element has been identified, the system searches for supporting elements to determine the confidence level.
Let’s assume that this imaginary email body has a keyword/primary element called “credit card” and three supporting elements – a secondary keyword called “expiry date”, a numeric string consisting of 16 repeating or non-repeating numbers, and another string consisting of four digits separated by a slash symbol.
The roles can also be reversed – for instance, the 16-digit string can pass as the primary element and the keyword “credit card” as the supporting element. Now the assumption has been made, the system will try to compute a pattern based on a predefined dictionary (i.e., a long-winded list of keywords associated with critical information curated by the deployed DLP solution).
Pattern establishment can be done in many ways, but proximity is, by far, the most efficient method. Okay, so what’s the deal with proximity? If the primary element (keyword or digit string) is close to the supporting elements (keywords or secondary digit string) the system recognizes one of the patterns associated with credit card information.
Come to think about it, this is a textbook example of an if-do operation – if the pattern’s recognized then enforce the policy. Considering that we have a primary element supported by three secondaries, the net force must, therefore, be “high confidence”.
EDMs can be ‘coached’ to identify patterns in content-heavy instances. Let’s consider the following – a document contains many examples of what can be construed as primary elements. Can the system establish a pattern? The answer is “yes” and here’s how:
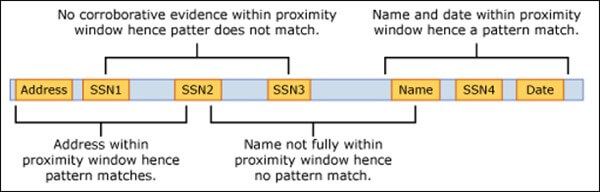
Deploying EDM comes with many benefits:
- Fewer false-positives results when querying big databases.
- High scalability potential.
- EDM can be used with most cloud services.
- Increased dynamicity.
Setting up EDM is a tri-pronged process. First, you will need to implement the EDM-based classification, a process that involves granting read-type access to the sensitive data stored on your server, translate the database schema in an XML format, create the rule package using the same format, and, finally, set the admin permissions via PowerShell. The second step’s all about hashing and uploading the data.
To safeguard privacy, all the data fed into the DLP will be hashes. To do that, you will need to create a security group and UA, grant local admin access to the machine, grant read-type access to the freshly hashed data, and process the refreshed data. Last – but not least- the parsed information has to be integrated with your DLP solution.
Since we already covered the advantages of EDM-based content filtering, we should also say a few words about probably the most important one – data exportation. EDM allows the user to export all sensitive data to any app tied to the DLP solution. On top of that, these files can be saved in .csv or .xls. So, what’s the catch? Well, a single .xls or .csv file can support up to 100 million rows of data, 32 fields per data search, and up to five columns at the user can earmark as searchable.
That’s how EDM works at a glance. If you’re interested in EDMing your DLP, check our Microsoft’s tech guide on how to set up Exact Data Match with Office 365 E5.
Regular Expressions (REGEX)
This content-aware technique really takes me back. Remember your first lessons in database manipulation? I don’t want to say that I’m that old, but back in my days, we used to write entire command lines to query one item in a very, very small FoxPro DB. Back to Regex – short for regular expression, regex is a string of text that allows the user to establish searching patterns. Naturally, these patterns will aid you in managing text, locating items, and matching chunks of data.
Many programming languages – Pearl, for instance – utilize regular expressions for data manipulation. Mastering them takes a while because it’s as close to statistics as you’re ever going to get, but the technique alone is invaluable, especially if you work with large chunks of text. The major advantage of Regex is that it can be used with virtually any text editor out there, including Notepad. So, what does Regex looks like?
For showcasing purposes, I’m going to borrow ComputerHope’s Regex e-mail matching example. Here it goes:
/[\w._%+-] +@[\w.-] + \.[a-zZ-Z]{2,4}/
Looks quite confusing or what would appear on the screen if a cat were to walk all over your keyboard. Allow me to break it down for you. So, the long-winded thingamajig found within the two “/” signs is the expression your machine must execute when querying a text for expressions or primary elements matching patterns associated with email addresses. We can break it down even more:
- The argument
[\w._%+-]instructs the machine to match any type of character found inside the brackets. - The argument
\wfound at the beginning of the bracket will instruct the machine to match regular alphanumeric characters. This includes the letter from A to Z (both upper and lower case) and any number from 0 to 9. - The
“+”argument found before the“@”sign will instruct the machine to match as many times as possible. Naturally, the “@” will match anything containing the “@” symbol. The same goes for the period symbol. - The
“[a-zZ-Z]”argument will instruct the machine to match upper- and lower-case letters, starting from “A” and going all the way up to “Z”. - The “
{2,4}” arguments will instruct the machine on how many is should perform the matching operation. In this particular example, it should match at least two times, but should not exceed the fourth pass.
This Regex expression is starting to make more sense, doesn’t it? If you focus on the structure, as a whole, you can make out something that resembles an email address: /[\w._%+-] –>username, /[\w._%+-] +@[\ –> mail server and [a-zZ-Z]{2,4}/ –> Top-level Domain.
Basically, this Regex has three components: one that matches usernames, another one that matches email server names, and the last one that searches for TLDs.
As I’ve mentioned, Regex does not require a sophisticated setup in order to match items. In theory, you can Regex-match items stored inside a plaintext Notepad document or locally-stored .csv files. Other advantages:
- Cross-compatibility (can handle any Operating System and language)
- UNIX-friendly.
- More ‘editable’ compared to regular code.
- Easier to understand compared to regular code.
- Regex can replace regular code. The ratio’s around 1:100 (i.e., one Regex line carries the same instructions as 100 lines of code).
Heimdal® Network DNS Security
- No need to deploy it on your endpoints;
- Protects any entry point into the organization, including BYODs;
- Stops even hidden threats using AI and your network traffic log;
- Complete DNS, HTTP and HTTPs protection, HIPS and HIDS;
Data Prevention Policies & Parting Thoughts
As the end’s in sight, I’ve thought about getting in a few lines about data prevention policies. For those unfamiliar with the topic, a DLP policy is a set of user-defined rules that regulate how data and informational streams are handled within and outside of your organization. Hashing sensitive data before uploading it to the company cloud is a great DLP policy example.
Policies can help you enforce compliance, maintain privacy, and root out instances that could turn into liabilities. In DLP, we need policies to homogenize sensitive information streams (i.e., confidential info can be spread across many locations such as exchange servers, clouds, applications), prevent intentional or unintentional data leaks, keep tabs on sensitive information residing in desktop applications, and increase productivity levels.
As to the latter aspect, it’s very important to train your employees in compliance, but such endeavors, which usually take the form of online classes or (sterile) seminars, can interfere with their duties. DLP policies can educate and, at the same, free up your employee’s time.
Quiz time: what does a DLP policy look like? Nope, it’s nothing like the Scroll of Truth or the cyber-version of the Necronomicon. Roughly speaking, it’s a trigger. And what does a trigger need? Conditions and actions, of course. A DLP policy needs a set of conditions, a set of actions to perform when the user-defined conditions are met, and a location. So DLP =Location + Condition + Action. Okay, that’s not the actual wireframe, but you get the point.
Location
Refers to the place where data classified as sensitive can be found. Microsoft’s DLP policy documentation mentions several instances that can pass off as locations – Microsoft Cloud App Security, devices running Windows 10, MS Teams and channel instant messages, accounts tied to OneDrive, SharePoint accounts and sites, and exchange email. Location can be trimmed down even further by applying inclusion or exclusion filters (e.g., sites, instances, groups, accounts, distribution groups, and so on).
Conditions
Life may be the ultimate unending list of “what-ifs” and “what coulds”, but still doesn’t hold a candle to computer language. DLP what-ifs are essential to make out the context and determined whether or not a set of actions can be applied. Of course, conditions would be pointless outside the actual content.
Now, in DLP, conditions can be utilized to pinpoint the (content)carrier of one or more types of sensitive information, read out labels, determine the owner or owners of that content, ascertain status (i.e., is it shared? If so, with whom is it shared? Is the content shared outside of the company? If true, who shared the content outside the company or, better yet, who is the person outside the company looking up the sensitive information?).
As you can clearly see, there are many things to consider when formulating a DLP policy\rule. However, you should bear in mind that more ‘granular’ DLP policies severely reduce the odds of a critical data breach.
Action(s)
If location is valid and all conditions are met, the DLP can execute a set of user-defined actions. Since we’re dealing with data loss prevention, the most common action type is “restrict”. Most DLPs permit three types of restrictive actions: restrict access to X content for everyone, restrict access to persons located outside the organization, and restrict access to anyone who has the link (i.e., there’s a “but” in there, just to clarify things).
Before I go, there’s one more thing I want to address: connective security. DLP is not all-encompassing; keep in mind that this system was designed to minimize the number of company policy violations, not to safeguard your endpoints and networks against cyber-aggression. Even the most fine-tuned DLP finds itself helpless when confronted with a worm or a trojan hiding behind a carefully forged macro.
For all your security needs, I highly encourage you to see connective cybersecurity in order to cover all attack vectors. Heimdal™ Security’s Threat Prevention Network guards your network’s perimeter with its powerful DNS traffic scanner, Ransomware Encryption Protection breaks the attack chain in case of a ransomware attack, and our Next-Generation Antivirus & MDM roots out every piece of malicious code that managed to evade the detection grid.
Hope you’ve enjoyed my article on DLP content-based techniques. If you haven’t done so already, be sure to check out my other article on how to choose the best data loss prevention solution for your company (link is in the intro). As always, stay frosty, stay safe, smash that subscribe button, and reach out to me if you have any questions, comments, or rants.




