 Network Security
Network Security
 Vulnerability Management
Vulnerability Management
 Privileged Access Management
Privileged Access Management
 Endpoint Security
Endpoint Security
 Threat Hunting
Threat Hunting
 Unified Endpoint Management
Unified Endpoint Management
 Email & Collaboration Security
Email & Collaboration Security



Contents:
Machine learning is a term usually mentioned in contexts that actually refer to artificial intelligence or is used as a synonym. Let us have a closer look at what the terms artificial intelligence, machine learning, and deep learning (another common notion used in relation to AI) really mean and how machine learning can be useful in cybersecurity.
What Is Machine Learning?
Machine learning is a technique used for teaching a computer to learn from its inputs without the need for explicit programming in every situation. Reasoning, finding meaning, generalization, and learning from past experience are all processes that are typically associated with intelligent beings and represent the goals of computers or computer-control devices that fall under the category of artificial intelligence.
In other words, AI is the machine’s ability to carry out human-like reasoning tasks, while ML is the approach used to teach a machine to think, act, and react just like a human being would.
The other term introduced at the start of this article, deep learning, refers to a set of approaches for implementing machine learning that detects patterns of patterns, such as image recognition. The systems first detect object edges, then a structure, then an object type, and finally the object itself.
Machine Learning Techniques
There are two main categories of machine learning algorithms, as can be seen in the following image:
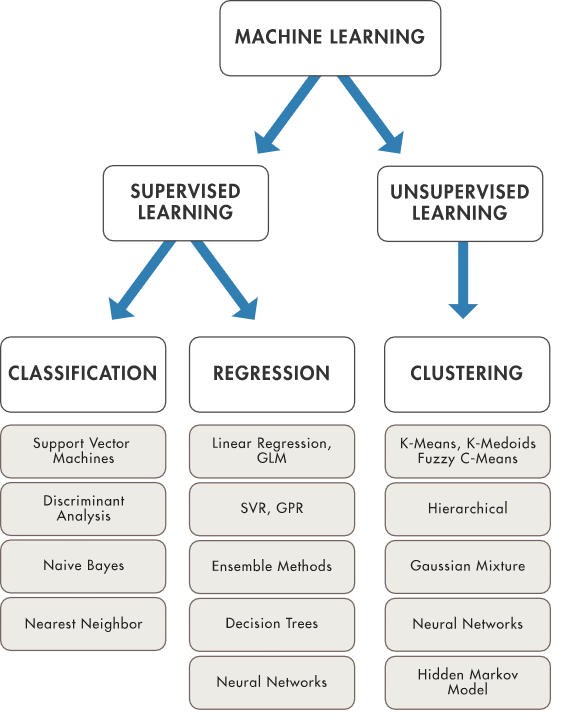
What is an algorithm, first of all?
Also known as models, algorithms are mathematical expressions that represent data in the context of a business problem. The goal is to gain insights from this data.
In supervised learning, you know what you want to teach a machine before you start. This usually entails exposing the algorithm to a large amount of training data, allowing the model to study the output, and fine-tuning the parameters until the desired results are achieved. The machine can then be put to the test by allowing it to generate predictions for a “validation data set,” which is simply new data that hasn’t been seen before.
In unsupervised learning, machines investigate a set of data. The computer then seeks to identify hidden patterns that link numerous factors after the initial exploration. This learning strategy can help with data classification into categories based only on statistical criteria. Unsupervised learning is substantially faster and easier to apply than supervised learning because it does not require large data sets for training.
Among some of the most important machine learning methods, we mention dimensionality reduction, transfer learning, reinforcement learning, and natural language processing.
Dimensionality reduction
With dimensionality reduction, the least important information is removed from a data set, in order to make the data set manageable.
Transfer learning
Transfer learning is the process of adapting a previously trained neural network to a new but comparable task by reusing a portion of it. You can transfer a fraction of the trained layers and mix them with a few new layers that you can train using the data of the new task once you’ve trained a neural net using data for a task. The new neural net can learn and adapt fast to the new task by adding a few layers.
Reinforcement learning
Reinforcement learning helps agents learn from experience. It implies the recording of actions in a set environment and the use of a trial-and-error approach. Because it doesn’t require information in advance, you can utilize RL when you have little to no past data regarding an issue (unlike traditional machine learning techniques. You learn from the data as you go with an RL framework.
This technique of machine learning helped IBM’s Deep Blue defeat the best human chess player in 1997.
Natural language processing
Natural language processing (NLP) “deals with the interaction between computers and humans using the natural language” and can be found at the foundation of applications like Google Translate, Microsoft Word and Grammarly, Siri, Cortana, Alexa.
Machine Learning in Cybersecurity
Machine learning can drive cybersecurity forward by:
- detecting harmful activities far more quickly and prevent attacks from even starting;
- assessing threats against mobile endpoints;
- recognizing risks, evaluating the network, and minimizing warnings,
- automating repetitive security processes, freeing up time for IT employees to focus on more critical responsibilities.
- Machine learning could also be used for closing zero-day vulnerabilities: “Some believe that machine learning could help close vulnerabilities, particularly zero-day threats and others that target largely unsecured IoT devices. There has been proactive work in this area: A team at Arizona State University used machine learning to monitor traffic on the dark web to identify data relating to zero-day exploits, according to Forbes. Armed with this type of insight, organizations could potentially close vulnerabilities and stop patch exploits before they result in a data breach. “
How do cybersecurity companies use machine learning nowadays?
- machine-learning techniques are employed to detect cyber risks fast(er);
- for analyzing large volumes of data (such as internal network activity, known bad sites, and suspected malware)
- for converting data points into a behavior map, which serves as a visual picture of a computer network and indicates potential risks;
- for automating threat response capabilities.
Machine Learning in Cybersecurity – Advantages and Disadvantages
When it comes to machine learning in cybersecurity, we have seen that it might be of great help to an industry that must always try to get ahead of its time and face the future. This does not mean that the use of machine learning in cybersecurity does not have any disadvantages. Let’s have a look!
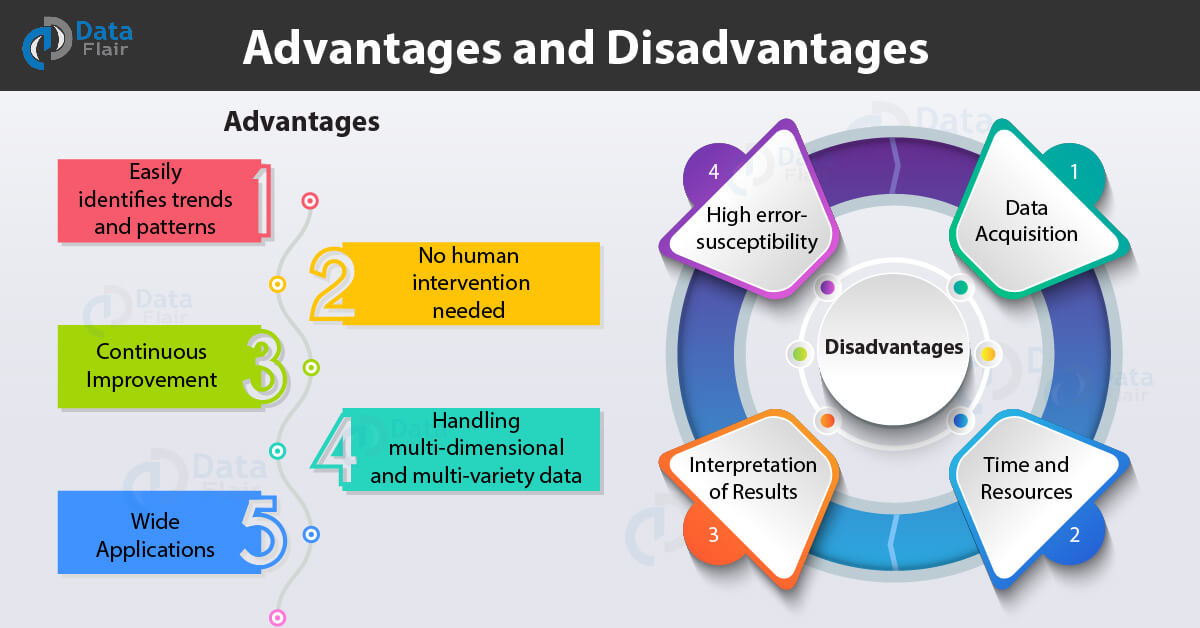
Advantages
- Machine learning can swiftly identify trends and patterns from large volumes of data. Moreover, it can pinpoint a causal relationship between events.
- Machine learning brings the advantage of automation. There will be less or no human interaction needed, because by giving the machines the ability to learn, we also give them the ability to make predictions and improve the algorithms on their own account.
- By learning from experience, machine learning algorithms continuously improve themselves and become more accurate and more efficient, which leads to making better decisions.
- Machine learning algorithms are also excellent at dealing with multi-dimensional and multi-variety data, even in dynamic or uncertain environments.
- Machine learning can be used for a wide range of applications, from healthcare to cybersecurity, for example. As Data Flair says, “where it does apply, it holds the capability to help deliver a much more personal experience to customers while also targeting the right customers.”
Disadvantages
- Machine learning requires a large amount of data to train on, data that is both inclusive and unbiased, as well as of high quality.
- Machine learning necessitates more computing power, as well as sufficient time for algorithms to learn and evolve.
- Data interpretation might also be difficult at times. It’s critical that the appropriate algorithms are chosen.
- Machine learning is prone to making mistakes. Assume you’re training an algorithm with data sets that aren’t large enough to be inclusive. As a result of a biased training set, you end up with biased predictions.
Heimdal™’s Machine Learning
Machine learning represents the foundation of one of Heimdal™’s most innovative products, the Threat Prevention module that can be used for both endpoint and network. Our solution focuses on detecting and preventing threats at a DNS level, representing another layer of security, besides the antivirus. Its Threat-to-Process Correlation (TTPC) capabilities can identify even the stealthiest process and sever the connection to the Command & Control server to prevent infection.
![]()
Heimdal® Network DNS Security
Machine learning algorithms are also used in our Next-Gen Antivirus, in the second stage of scanning and identifying even the most advanced threats. The stages are: Local File/Signature & Registry scanning, Real-Time Cloud Scanning, Sandbox, and backdoor inspection, Process Behaviour-based scanning.
Wrapping Up
As we have seen, machine learning can be a powerful tool for achieving exceptional cybersecurity, if used right. Thanks to automation, machine learning can increase the ability to respond to threats and save precious time (ergo, money) for the IT department of any company.
Drop a line below if you have any comments, questions, or suggestions – we are all ears and can’t wait to hear your opinion!
P.S.: Don’t forget to follow us on LinkedIn, Twitter, YouTube, Facebook, and Instagram to stay up to date with everything we have prepared for you!


Elena Georgescu is a cybersecurity specialist within Heimdal™ and her main interests are mobile security, social engineering, and artificial intelligence. In her free time, she studies Psychology and Marketing. Some of her guest posts on other websites include: cybersecurity-magazine.com, cybersecuritymagazine.com, techpatio.com



